Bashing it out
A quick script to shave repetitive tasks off a GitLab Flow style branch model.
Contents:
Background
The branching strategy we use at Anneal is something I’ve arrived at after a few years of iteration across projects.
It follows a similar pattern to GitLab Flow, but isn’t quite the same. Like GitLab Flow, we have both environment and feature branches, and things are merge based—so rebasing isn’t something that’s an overly routine part of the workflow. However, the branch setup differs a little bit, particularly in how it relates to deployed application environments.
For context, we generally work with GitLab, hence we refer to merge requests rather than pull requests, and the basic setup is as follows:
- We run three deployed environments for each project, and have three corresponding protected branches:
development,staging, andproduction.- The
developmentenvironment exists primarily to improve the developer experience when working with Lambda, SQS, and other AWS services that are a pain to develop around and/or test locally.
- The
- The effective master branch is
development. It’s the default branch for all projects, and all feature branches branch off it. - On merging into
developmentorstaging, we unlock the deployment oriented jobs in our pipeline, and they handle the relevant build/deploy work. - For
production, things are driven by tags. To run a production release, we create a release branch fromstaging, then raise a merge request to merge that intoproduction. Once that merge has been accepted, tagingproductionwith the relevant version number triggers the deployment job(s).
New development work is handled with feature branches, and if we really feeel the need to run with hotfix branches, that is also possible.
The broad system looks something like this:
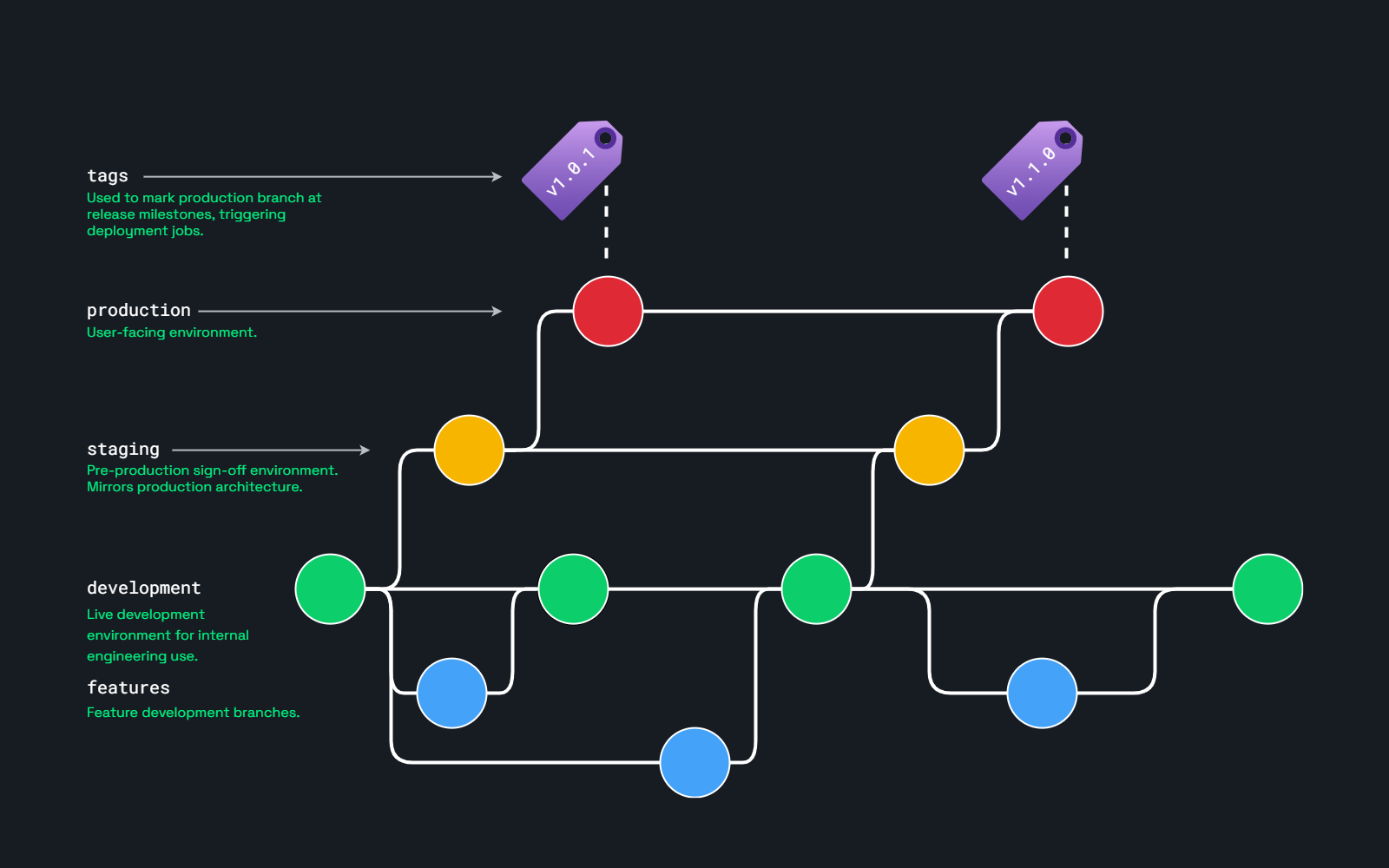
Obviously this doesn’t include any detail about how we deploy infrastructure, which has some overlap… but here the focus is how we handle application updates.
Changelog
I’ve kept a changelog for every project I’ve worked on since I first came across one. Beyond providing an easy to skim record of changes, we also include links to relevant tickets and documentation.
Beyond this, however, they have proved an incredibly useful mechanism for managing any misplaced concerns about the pace of development. As someone who wants to do high quality engineering work as quickly as possible, I routinely stress about release cadence, timelines, and general pace of progress. Being able to pull up a single document that lays out what work has been completed, and on what timeline, is a very straightforward way of keeping that stress in perspective.
The problem with CHANGELOG.md
The only downside we face with keeping a changelog, aside from the odd requirement to nudge colleagues to update the
thing as part of the review process (see below), is that we make changes to the CHANGELOG.md file quite late in the
process—immedately prior to merging to the production branch. This means that changes here are not replicated in our
staging or development branches without some manual intervention.

For context, when we release to production from staging, the process that’s followed is:
- Create a
production-release/vX.Y.Zbranch fromstaging. - Update the changelog to include this new version number.
- Until this point, all changes since the prior release will appear under an ‘Unreleased’ heading.
- Raise a merge request to merge
production-release/vX.Y.Zintoproduction. - Once that merge request has been accepted, tag
productionwith theX.Y.Zversion number. - Wait for deployment to complete.
After this, we raise two merge requests: one to merge production into development, and one to merge production
into staging.
These serve to keep the changelog in sync across branches, making sure development and staging are up-to-date, and
have captured the changes we maed to CHANGELOG.md on our production-release/vX.Y.Z branch.
However, this process is pretty clunky in GitLab. It takes a few minutes per branch, and it’s easy to forget. When you might be doing this a couple of times a day, it gets quite frustrating.
Bash script to the rescue
Thankfully, GitLab have a nicely documented API we can lean on to take some of the clunk out of this.
Our basic requirements are:
- We need a personal access token. We can set this up in the GitLab console, then save it off as an environment variable.
- We need the ID of the project in question. On your project overview page, this is visible below the project name.
- We need to know what endpoint to hit, and what data to send. For that, we can check the merge requests section of the docs.
Once we’ve pulled all that together, we can set about doing what we want:
- Loop through our set of two target branches:
developmentandstaging. - For each target branch, raise a merge request to merge
productioninto that branch.
If we sprinkle in some colour and some nice messaging, we end up with something like this:
#!/bin/bash
set -e
# Set some handy color ANSI codes.
RED='\033[0;31m'
BLUE='\033[1;34m'
ORANGE='\033[0;33m'
NC='\033[0m'
# Define project ID and relevant branch names.
PROJECT_ID="<YOUR_PROJECT_ID>"
SOURCE_BRANCH="production"
TARGET_BRANCHES=("development" "staging")
# Build GitLab API endpoint.
ENDPOINT_URL="https://gitlab.com/api/v4/projects/$PROJECT_ID/merge_requests"
# Loop through each target branch and create the MR.
echo -e "----------"
echo -e "Creating merge requests using endpoint $ENDPOINT_URL"
for TARGET_BRANCH in "${TARGET_BRANCHES[@]}"; do
echo -e "\nCreating merge request: ${BLUE}${SOURCE_BRANCH}${NC} -> ${ORANGE}${TARGET_BRANCH}${NC}"
response=$(
curl \
--write-out '%{http_code}' \
--silent \
--output /dev/null \
--request POST \
--header "PRIVATE-TOKEN: $GITLAB_ACCESS_TOKEN" \
--data "source_branch=$SOURCE_BRANCH&target_branch=$TARGET_BRANCH&title=Merge $SOURCE_BRANCH into $TARGET_BRANCH" \
"$ENDPOINT_URL"
)
if [[ "$response" -ne 201 ]] ; then
echo -e "Operation failed. Received code ${RED}${response}${NC}"
else
echo -e "Operation succeeded."
fi
done
echo -e "----------"
I keep a version of this file in the root of each project repo. Once I’ve updated the changelog on
production-release/vX.Y.Z, and merged that into production, it’s as simple as hopping into the terminal, running
./post_release.sh, and letting the script do its thing.
Note that if you’re creating this file from scratch, you’ll need to make it executable with chmod +x post_release.sh.
That’s it. No more UI, no more clicking, no more waiting for GitLab to take six months to load your list of branches.